Claude Projects Scope Files and Instructions for Long Threads — But Project Context Is Not a Shared Agent Memory Layer

Claude Projects let users attach documents, style guides, and standing instructions so multi-turn work stays on brief without pasting the same preamble daily. For research, writing, and product strategy, that scoping is a clear upgrade over stateless chat tabs. The limitation that keeps showing up in production is not model capability — it is memory.
Project folders organize *human-selected* context; they are not designed as the system of record for *machine-consumed* memory across agents and APIs.
Platform metrics usually flip in predictable ways once Claude lands in a real org: pull requests merge faster, support macros handle more tier-one questions, and incident bridges spend less time re-explaining architecture. Those wins are real. They also hide a second curve — coordination cost across squads — that only appears when multiple agents, dashboards, and humans all need the same ground truth about customers, services, and policy exceptions.
Within six to twelve months, engineering directors describe the bottleneck shifting from "smarter models" to "knowledge plumbing." That is where episodic chat, static config, and one-off spreadsheets stop scaling. A deliberate AI agent memory tier becomes the difference between repeating discovery and compounding it.
None of this diminishes what Anthropic ships: capable models, thoughtful safety defaults, and APIs that meet production expectations. It simply clarifies the division of labor — models reason; memory systems retain — so teams stop blaming "hallucinations" for what is often missing ground truth.
Claude Projects: What Teams Get Right (And What Still Breaks)
Leaders adopt these patterns because they reduce variance: fewer surprise behaviors, faster reviews, clearer ownership of prompts and tools. The developer experience improves measurably when agents stop rediscovering the same repository trivia every Monday.
Security and compliance teams appreciate explicit boundaries: what tools an agent may call, which subnets it may reach, and how prompts are versioned. Product teams appreciate faster iteration on UX. None of that removes the need for durable recall when the same customer story spans sales, support, and engineering — each with its own Claude deployment.
Yet when the same teams scale to dozens of agents, environments, and compliance zones, they hit coordination debt. Information discovered in one workflow rarely becomes a first-class object another API can query. That gap is structural: conversation and config files are not a substitute for a MemU Agentic Memory Framework-style layer that stores entities, relationships, and outcomes with retrieval tuned for agents.
What Claude Projects Does With Memory Today
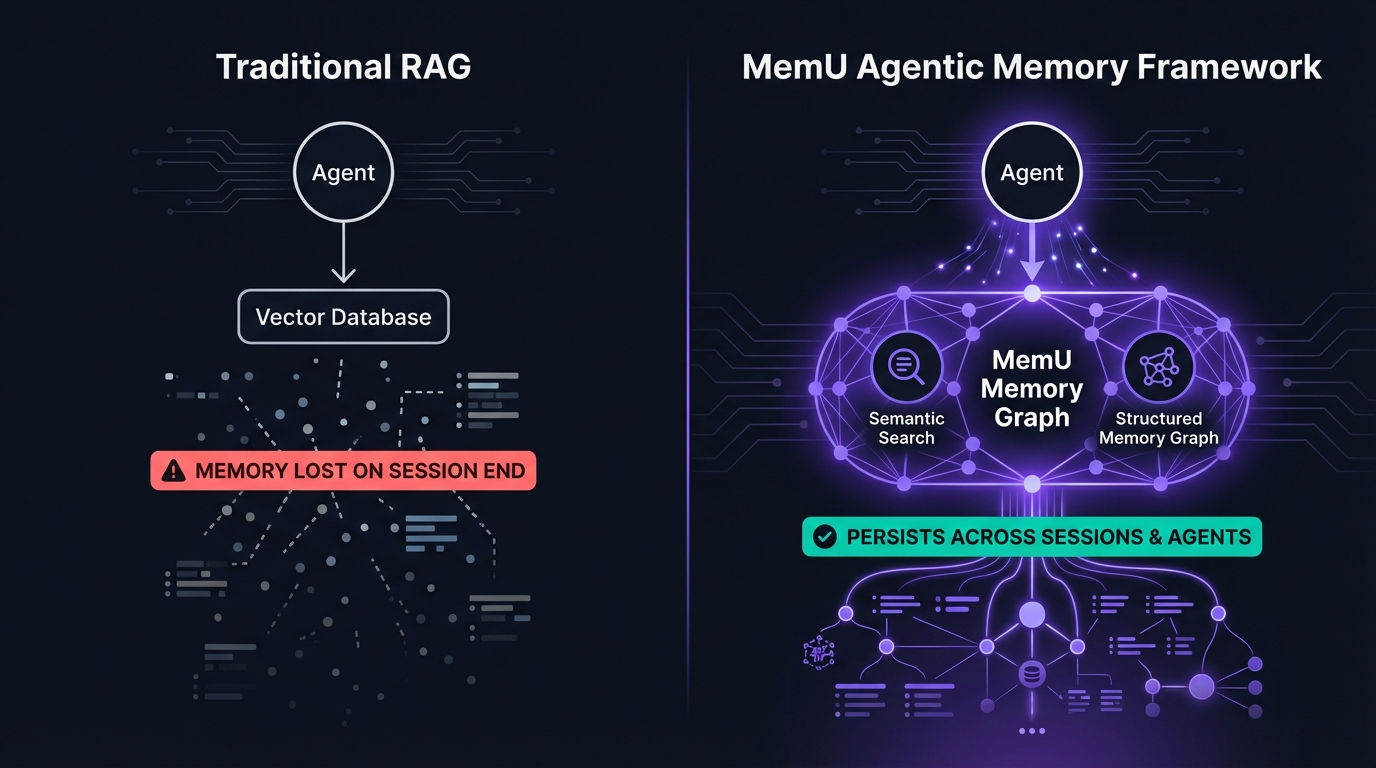
Knowledge lives in uploaded files and conversation history bounded by context limits and UI boundaries. Parallel agents — a coding agent, a support bot, an analytics assistant — do not automatically read each other's project state. Notion AI workspaces, ChatGPT projects, and similar offerings share the pattern: helpful containment, not federated retrieval for automated systems.
Teams sometimes respond by enlarging context windows, adding more RAG chunks, or copying transcripts into wikis. Each patch helps a slice of users but increases cost, latency, or manual labor. None of them gives you relationship-centric recall — who approved an exception, which dependency version correlated with a failure, or how two tickets about the same account were actually one root cause.
**"Project scope helps people; production agents need an API-addressable memory graph that spans products and sessions."**
That is a category-wide pattern for frontier assistants — not a single vendor oversight. The fix is architectural: separate the loop that thinks from the store that remembers, then wire them with APIs agents already know how to call.
The MemU Agentic Memory Framework: A Different Architecture
The MemU Agentic Memory Framework integrates through HTTP APIs and SDKs so Claude-based stacks keep their existing routers, guardrails, and deployment patterns. You add retrieval calls where tool results would otherwise disappear — after merges, after incidents, after customer conversations. Marketing runs a Claude Projects hub with brand voice docs while engineering uses Claude Code on the same product. Neither side sees the other's resolved decisions unless someone manually copies summaries.
Differentiation comes from dual-mode retrieval: semantic search for fuzzy questions plus a structured memory graph for ownership, dependencies, and causality. Memories persist across sessions and can be shared across agents where policy allows, which matters when more than one automated worker touches the same customer or service. At scale, graph-aware recall typically outperforms dumping ever-longer transcripts into the context window.
Integration work stays bounded: most teams add memory writes at completion boundaries — PR merged, ticket closed, incident resolved — and memory reads at planning boundaries — new task, new session, new on-call rotation. That rhythm mirrors how humans debrief without forcing every token through a new database in real time.
Agents need fast loops and durable facts. The MemU Agentic Memory Framework is the substrate that keeps conclusions addressable after the chat ends — without pretending every token belongs in prompt caching or static markdown.
Head-to-Head: MemU vs. Claude Projects-Centric Stacks
Claude Projects alone: Clean boundaries for individual or team chat. Weak cross-product automation and cross-agent sharing.
Projects plus MemU: Decisions, rationales, and artifacts become memories other agents can query through APIs.
Compared with homegrown vector-only stores, MemU emphasizes relationships and provenance — fewer "similar but wrong" retrievals when multiple entities share overlapping language. Compared with doing nothing, it is the difference between repeating work and compounding it.
Latency-sensitive agents still win: you retrieve a small set of grounded memories instead of replaying entire threads. Precision-sensitive teams win: you attach citations and timestamps to memories for audit. Neither outcome requires ripping out Claude — it requires treating memory as its own service, the way you already treat auth and billing.
Empowering Claude Projects: Better Together
MemU does not replace your Claude stack; it makes that stack remember responsibly.
- Align Claude chat and code: MemU bridges narrative decisions from projects with implementation memory from repos.
- Audit trail: Structured memory records provenance beyond flat file uploads.
- Long-horizon programs: Quarter-long initiatives retain milestones without stuffing every file into one project.
Memory infrastructure can run with high availability so agents in always-on pipelines retrieve consistently — the same reliability bar teams already expect from observability and CI, applied to recall.
Postponing a memory layer often produces "smart but expensive" agents: they re-read the same files, re-query the same APIs, and re-summarize the same documents because no durable index captures prior conclusions. The cumulative token and labor cost usually exceeds the engineering time to wire structured writes at task boundaries. Treating memory as infrastructure — like metrics and feature flags — keeps Claude deployments economical as they grow.
Get Started with MemU
Pair Anthropic Claude with the MemU Agentic Memory Framework when your agents need cross-session, cross-team facts — not just longer prompts. Visit memu.pro to explore the API, or the GitHub repository to integrate memory into your existing agent code.
Tags: Claude Projects, Anthropic Claude, AI agent memory, knowledge scope, MemU AI, long-context chat